Screw the power law, embrace the power law
A couple of notable developments in the whole power laws and weblog discussion. Steven Johnson states that, ok, the distribution of influence in the weblog world follows a power law…now what? If we as participants in that network don’t want things to work that way, is there anything we can do about it?
Prompted by all the power law talk, David Sifry is now using non-linear equations to determine recent interesting weblogs and recent interesting newcomers for Technorati. The idea is that the distribution of weblogs is non-linear (the power law curve isn’t a straight line), so why not use non-linear equations to level the playing field a little.
What David is doing is actually why I graphed the Technorati data in the first place. I was trying to figure out how you could make the interesting blogs list not favor the top-linked sites all the time (200 new sites linking to Movable Type is not interesting considering it already has 6000 sites linking to it).
Here’s an email I sent David a couple of days ago:
“I started thinking about [the graph of the data] in relation to the Interesting Recent Blogs list and how it could be made more useful. Because it’s the biggest, Google is always going to be at the top of the list, and some little weblog with 4 new posts (out of a total of 6) is never going to get anywhere near the top. I was thinking that by analyzing the distribution of the links, you could introduce a adjustment factor based on the rank of the site relative to the #1 site. The problem is, I can’t remember enough of my college math to get from the power law equation to this magical adjustment factor. You might have better luck.”
The idea is that instead of using a quadratic or cubic equation that kinda fits the data, you use a power law equation generated by the data itself to exactly fit the data (or nearly so). The power law equation I derived using the limited sample of the top 100 list is:
y = 5989.8x^(-0.8309)
where y is the # of inbound blogs and x is the rank of the site. I plotted the top 100 data again and tried to fit three curves to it:
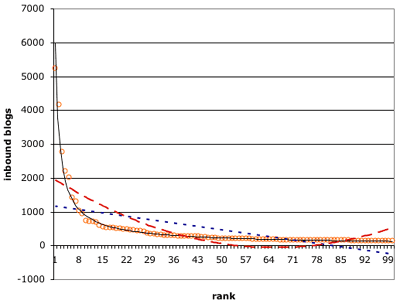
The dotted blue line is a linear equation, the dashed red line is a quadratic equation, and the solid black line is the aforementioned power law equation. As you can see, the linear and quadratic equations fit the data poorly. The R-squared for the linear equation is 0.31, 0.55 for the quadratic, and 0.99 for the power law equation. So the quadratic is an improvement over the linear equation, but neither compare to the excellent fit of the power law and the excellent results that would follow from using it for Technorati’s interesting recent blogs lists.
Reader comments
Seth WerkheiserFeb 12, 2003 at 10:24AM
My head hurts now.
BenFeb 12, 2003 at 10:43AM
Can you dumb it down a shade?
NickFeb 12, 2003 at 11:25AM
Makes sense to me. What I'm wondering is why we haven't been using the power law for rankings to begin with? I'm not trying to imply I would have come up with such a solution myself (far from it), but the idea that power laws work on the Web has been around for a while.
SHFeb 12, 2003 at 12:17PM
You'll win a Nobel if you solve this!
Dave SifryFeb 12, 2003 at 12:43PM
Jason,
You've hit it exactly. Thanks for doing the statistics to determine the best-fit curve! Now all I have to do (when I get a free minute) is see how to express the equation in a MySQL SQL call. :-)
Dave
AaronFeb 12, 2003 at 12:59PM
Hibbert: Homer, I'm afraid you'll have to undergo a coronary bypass operation.
Homer: Say it in English, Doc.
Hibbert: You're going to need open heart surgery.
Homer: Spare me your medical mumbo-jumbo.
Hibbert: We're going to cut you open and tinker with your ticker.
Homer: Could you dumb it down a shade?
TimFeb 12, 2003 at 1:10PM
I'm with Seth, Ben, and Aaron.
How about this: "We're trying to figure out a way to de-emphasize popular weblogs and give the little guys a chance, so that they don't become discouraged and stop reading weblogs altogether."
staceyFeb 12, 2003 at 1:48PM
But where is the equation that reflects blogs featuring pictures of cats? I need a definitive algorithm for the number of new blogs, hosted by Moveable Type, featuring photos of kittens under the age of 2 years, that blogroll Snazzykat. Can you whip those numbers up for me Wunderkind? I didn't think so.
Dave SifryFeb 12, 2003 at 3:08PM
Stacey,
Sure, easy.
y=0.
:-)
Dave
BenFeb 12, 2003 at 3:24PM
I just don't understand whether the data itself is useful information, or whether it's just a rhetorical question about which equation is best. Is the question basically already answered, and it's just Jason showing off his Excel and Iowan-educated math skills?
Ross MayfieldFeb 12, 2003 at 3:26PM
My post on Distribution of Choice was a little long winded, so let me sum up:
Not all links are created equal
Conversational relationships are not scale-free
Applying these principles reveals a Network Ecosystem Model that helps us understand the political economy of weblogs
John DowdellFeb 12, 2003 at 5:22PM
"If we as participants in that network don't want things to work that way, is there anything we can do about it?"
Sorry I don't have a good answer to that question, because I didn't see it, I'm reading some other blog other than yours today..... ;-)
(Gives a whole new meaning to the phrase "you the man!", huh?)
On the serious side, inequality in results isn't a significant problem for me so long as there are no artifical barriers to entry... so long as opportunity costs are reasonable. But I follow through with this philosophy in several realms, and I can see how being on the high end of a power curve could cause cognitive dissonance in those who think that *other* power-law distributions would benefit from regulation (despite all observable history to the exact contrary).
If you're *really* seeking a way to correct this, maybe providing links only by article citations and avoiding blogrolls could help loosen up the barriers-to-entry...?
jd
Tom CoatesFeb 12, 2003 at 7:15PM
So if I get this right, you're essentially trying to find a way of pointing out statistically significant spikes in the linkage to a weblog or site (rather than just measuring the quantity of said links). While it's a noble aim, isn't it fair to say that any and all links to a brand new weblog will be hugely statistically significant for their size?
ChrisFeb 13, 2003 at 8:10AM
I understand he math - I'm just wonderng why its important. Ultimately, I think the real power of blogs is going to be in enabling small group communications. Project blogs, internal company communications, maybe even a knowledge management system that actually works.
JeffFeb 13, 2003 at 9:55AM
Where does the type of post/blog influence its popularity? Dave Pollard brought up an interesting point when he told me that there seems to be a bias towards shorter-entry blogs, no matter how articulate or interesting the longer posts might be.
So, I'm curious how the type of entry is built into the math (can it be?) Or is all this just based on the number of links?
Martin ConaghsnFeb 13, 2003 at 5:04PM
This concept is truly fascinating, even if the numbers are difficult to understand.
I hope someone cracks it soon.
Since I started weblogging about two years ago, I've wrestled with the challenge of making my site more popular, whilst also maintaining a decent level of quality in the content, without being too derivative of other sites.
A few things have struck me about the popularity of certain sites, with particular reference to weblogs:
A weblog can be hit or miss, depending on your interests. I have about 50 or 60 weblogs in my favourites, yet I only visit about seven or eight of them on a daily basis. As Stan Laurel once said: you can take a horse to water, but a pencil must be lead.
Based on this, there's simply no way of making your weblog interesting to everyone and anyone, no matter how hard you try - especially if those people are just not interested in the content of your weblog.
This is very difficult to combat, since the weblogs I'm not interested in deserve to be promoted as equally as I think my own should be, especially if their content interests others.
However, I think it's a given fact that the popularity of a weblog can be instantly increased by the inclusion of an outbound link on another very popular weblog.
In my earliest days, Dan Gillmor linked to my site when I'd pointed out an error on one of his posts, and the traffic to my site shot up.
Perhaps the distribution of power could be assisted by something that relies on highly popular weblogs?
But would this be fair?
It's certainly not the responsiblity of people like Jason here to feel obliged to link to relative minnows like me.
Allowing the 'comments' pages on a weblog to be indexed is one possible way of achieving this - since people adding a comment to a popular site (like I'm doing here) can add their own website URL to the page, which counts as an inbound link as far as Google is concerned.
Despite all of this, I still feel that the most successful way to create a popular weblog, is to keep doing it, and keep doing it well. I'm talking almost every day here, but not obsessively so. Listing tools like weblogs.com help, but they can't make your site more interesting.
You need to have something worthwhile to say, something to show people and something to interest them.
You might not be able to please everyone all of the time, but in being prolific, your site's page count will naturally increase in size, and the potential combination of search terms on each of the pages in your site will increase the chances of it being found by a good search engine and subsequently linked-to on another site - especially if the content is good or interesting.
xianFeb 13, 2003 at 6:22PM
hey, by providing such good commentary (and graphic illustration) to this discussion, jason is just reinforcing his own popularity. dang it!
ry rivardFeb 13, 2003 at 9:15PM
Stop being so linear.
Just like Google proved it wasn't just meta tags and quantity of keyword apperance, any system of orgainizing weblogs needs to get that it isn't just links.
It's true that the currency of the internet is linkage but that is no way to find a new site because it requires a recommendation, usually one made by "higher powers" (such as yourself and other blockbuster blogs), then the link has to catch on to be picked up by either in-bound counters of the current systems (Technorati, Blogdex, et al).
This isn't the solution.
The solution must be a way to find similar content, and in the end that is what most people using the internet are looking for: Not just popular content but diverse entries (opinions, angels, etc) related to a particular subject.
Technorati, et al comes closer than some but it doesn't look at the context of the link (a link on your sidebar is given the same weight as three paragraphs on someone else's site).
What is needed is a system that weighs a little of everything: who's who of the link to (ala` PageRank); popularity of the link (ala` Blogdex); the spike (ala` your equation); placement of reference (in a paragraph tag, standing alone as in a sidebar); and, most importantly, by subject (ala` Google News). Only then will the system serve best the users by finding best the blogs that are related and interesting.
JeffFeb 14, 2003 at 11:44AM
Martin, you bring up an interesting point. If the nature of the net allows us to create "niche markets," then why are we so interested in overall popularity?
Shamit BagchiFeb 14, 2003 at 11:53AM
What Martin Conaghsn says is perfect : The interests of readers and bloggers and sometimes search based on topics is a very important component - If a person's attention is captured he is sure to come back again
'CONTENT MATTERS' :
JUST LINKS TO NEWS WONT DO, YOUR OWN GENUINE ARTICLES AND JOTTINGS ARE AS MUCH IMPORTANT. Write your mind out . . .
SIMPLE EQUATION: You like what I blog (and my commentry!) plz link to me and you do a virtual LINK UP.
All else is statistics to do and say is the nastiest thing in the nicest way as the saying goes . . .
Equations can only estimate and no artifial attempt should be made to reverse the trend.
Linking purely for the sake of giving those under you an impetus (call it 'LINKING UP' ?) is a bad idea - like as though they were beggars and you were doing a favour
Let 'em (minnows) make their own debuts followed by active attempts at gaining recognition via true (and as Martin rightly said continously updated) content/articles and other methods (Like COMMENTS Eh ! ;-) )
To get a bit more PHILOSOPHICAL 'A true talent always shines, even if . . . whatever'
SHAMIT @
BLOGMIND - At Intellect's Edge of Chaos
vanilla_gazeboFeb 22, 2003 at 4:02PM
came to visit your site out of curiosity after reading We've Got Blog: How Weblogs Are Changing Our Culture in which kottke.org was mentioned. I'm a demi-blogger, with a page hosted at a free site based on the livejournal code, and a recent interest in computers and web-design.
This thread is closed to new comments. Thanks to everyone who responded.