kottke.org posts about Google
Book on Truth in the Age of A.I. Contains Quotes Made Up by A.I.:
The author of a nonfiction book about the effects of artificial intelligence on truth acknowledged on Monday that he had included numerous made-up or misattributed quotes concocted by A.I.
The author, Steven Rosenbaum, whose book “The Future of Truth” was released this month to great fanfare, incorporated more than a half-dozen misattributed or fake quotes in sections of the book reviewed by The New York Times.
The Times asked Mr. Rosenbaum about the quotes on Sunday and Monday. On Monday night, Mr. Rosenbaum acknowledged in a statement that the book had “a handful of improperly attributed or synthetic quotes” and said that he had started his own investigation.
Nobel Laureate Olga Tokarczuk Apparently Used AI to Write Her Latest Novel:
In a recent interview (conducted and published in Polish), Nobel Prize-winner Olga Tokarczuk admitted to using AI in her creative process.
The writer Maks Sipowicz, who drew attention to the interview on Bluesky, translated a few of salient bits: “When writing my latest novel… I asked this advanced model what kind of songs my protagonists would be listening to at a dance, a few dozen years ago, and AI gave me a few titles,” Tokarczuk told the interviewer. “Often I just ask the machine, ‘darling, how could we develop this beautifully?’ Even though I know about hallucinations and many factual errors in the algorithms in terms of economics and hard data, I have to add that in literary fiction this technology is an advantage of unbelievable proportion.”
Google Search As You Know It Is Over:
At its Google I/O conference on Tuesday, Google unveiled an AI-powered overhaul of Search centered around a reimagined “intelligent search box” — what the company describes as the biggest change to this entry point to the web since the search box debuted more than 25 years ago.
Instead of returning a simple list of links, Google Search will drop users into AI-powered interactive experiences at times. Google is also introducing tools that can dispatch “information agents” to gather information on a user’s behalf, along with tools that let users build personalized mini apps tailored to their needs.
The resulting experience will no longer look much like how people envision Google Search, which has long been defined by ranked links to websites that have the information you need.
Gemini Is in Danger of Going Full Copilot:
Gemini has a creep problem.
A few years ago, that little sparkle icon started showing up in all of our Google apps. Gemini in your inbox! Gemini in your Google Drive! It was slow at first, and easy enough to tune out, but something has changed in the past few months. Gemini is creeping. It’s showing up in all kinds of places at a relentless pace, and personally, it’s starting to really cheese me off.
An actual screenshot from Google just now (a la Charlie Jane Anders):

Commencement speakers at recent graduations get booed for casting AI in a positive light:
And that’s just today. 😰
Megan Gray on a disturbing piece of information that was revealed in the antitrust case against Google: their search engine replaces some search queries with others that generate more commercial results (and therefore more money for the company). Here’s how it works:
Google likely alters queries billions of times a day in trillions of different variations. Here’s how it works. Say you search for “children’s clothing.” Google converts it, without your knowledge, to a search for “NIKOLAI-brand kidswear,” making a behind-the-scenes substitution of your actual query with a different query that just happens to generate more money for the company, and will generate results you weren’t searching for at all. It’s not possible for you to opt out of the substitution. If you don’t get the results you want, and you try to refine your query, you are wasting your time. This is a twisted shopping mall you can’t escape.
Yuuuck. I think it might be time to switch away from Google search — its results have been getting worse for years and it seems like the company doesn’t care too much about fixing it. I’ve been hearing good things about Kagi and there’s always DuckDuckGo.
Update: Several people wrote in noting that Gray’s article was an opinion piece, not reported, and that there was no corroboration of her claim of Google’s query switcheroo. For their part, Google denies the claim: Per Platformer:
Google does not delete queries and replace them with ones that monetize better as the opinion piece suggests, and the organic results you see in Search are not affected by our ads systems.
(thx, andy)
Update: Wired has removed the story from their website:
After careful review of the op-ed, “How Google Alters Search Queries to Get at Your Wallet,” and relevant material provided to us following its publication, WIRED editorial leadership has determined that the story does not meet our editorial standards. It has been removed.
The Internet Archive has a copy of the original piece. Charlie Warzel has more in a report from the Atlantic. (thx, andy)
Just about everything on the web is on TikTok, and going viral there too, so it shouldn’t be a surprise that people who’ve been laid off are there too, trying to figure out what it all means.
Part of me is cynical about this. You mean that as people, we’re so poorly defined without our jobs that our only resource is to grind out some content about it? But on the other side of the coin, making content is what human beings do. Other animals use tools, but do they make content? Apart from some birds, probably not.
My favorite TikTok layoff video is by Atif Memon, a cloud engineer who offers a clear-eyed appraisal of her situation:
“At the company offsite, we celebrated our company tripling its revenue in a year. A month later, we are so poor! Who robbed us?”
“Even if ChatGPT can take away our jobs, they’ll have to get in line behind geopolitics and pandemic and shareholders and investors. I lost my job because the investors of the company were not sure will become 400x in the coming year. ‘How will we go to Mars?’ Someone else lost their job because the investors thought ‘Hmm, if this other company can lay off 12k people and still work as usual, shouldn’t we also try?”
“Artificial intelligence can never overtake human paranoia and human curiosity. AI can only do what human beings have been doing. Only humans can do what no human has done before.”
A lot to chew on in four minutes.
Update: Apparently this is not native to TikTok, but was posted to YouTube by a comedian, Aiyyo Shraddha. It really is a perfect TikTok story! The video is a ripoff.
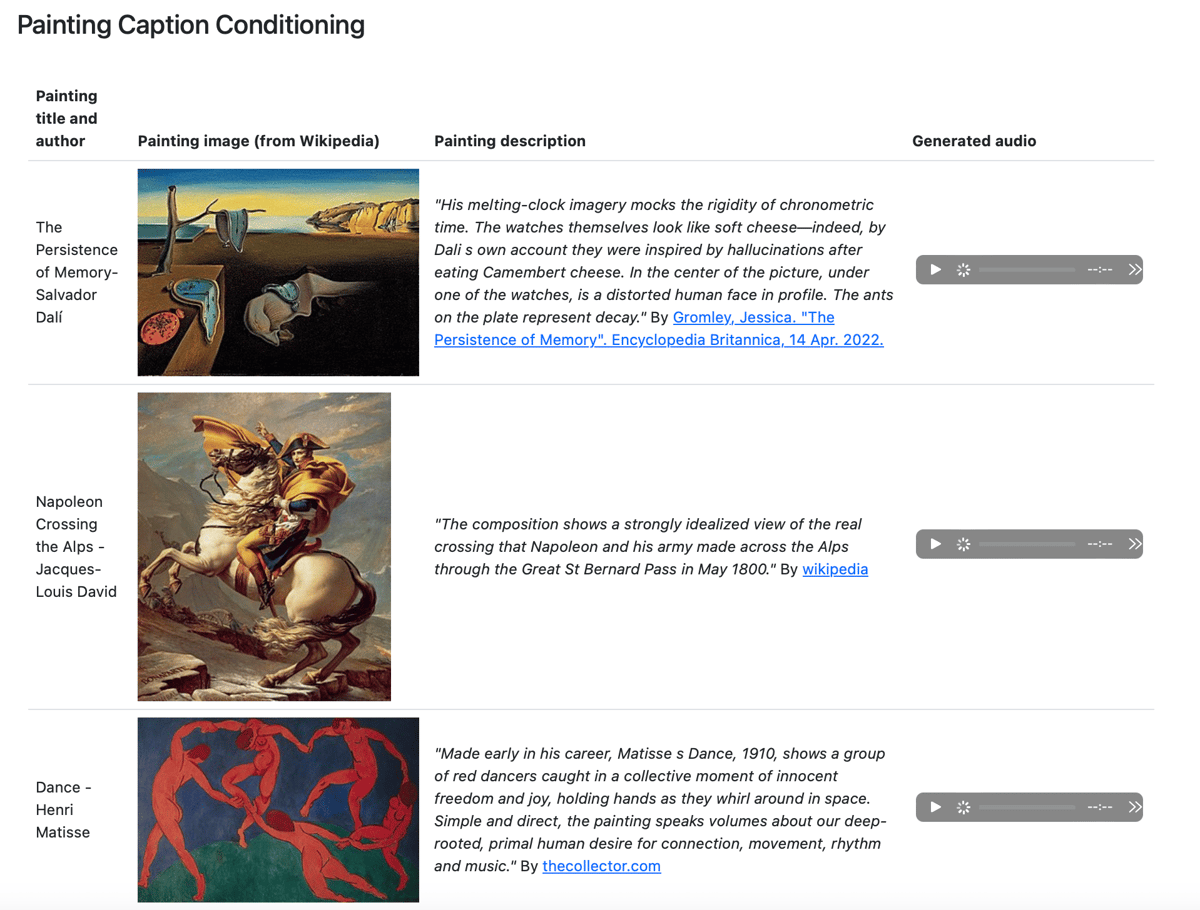
Google Research has released a new generative AI tool called MusicLM. MusicLM can generate new musical compositions from text prompts, either describing the music to be played (e.g., “The main soundtrack of an arcade game. It is fast-paced and upbeat, with a catchy electric guitar riff. The music is repetitive and easy to remember, but with unexpected sounds, like cymbal crashes or drum rolls”) or more emotional and evocative (“Made early in his career, Matisse’s Dance, 1910, shows a group of red dancers caught in a collective moment of innocent freedom and joy, holding hands as they whirl around in space. Simple and direct, the painting speaks volumes about our deep-rooted, primal human desire for connection, movement, rhythm and music”).
As the last example suggests, since music can be generated from just about any text, anything that can be translated/captioned/captured in text, from poetry to paintings, can be turned into music.
It may seem strange that so many AI tools are coming to fruition in public all at once, but at Ars Technica, investor Haomiao Huang argues that once the basic AI toolkit reached a certain level of sophistication, a confluence of new products taking advantage of those research breakthroughs was inevitable:
To sum up, the breakthrough with generative image models is a combination of two AI advances. First, there’s deep learning’s ability to learn a “language” for representing images via latent representations. Second, models can use the “translation” ability of transformers via a foundation model to shift between the world of text and the world of images (via that latent representation).
This is a powerful technique that goes far beyond images. As long as there’s a way to represent something with a structure that looks a bit like a language, together with the data sets to train on, transformers can learn the rules and then translate between languages. Github’s Copilot has learned to translate between English and various programming languages, and Google’s Alphafold can translate between the language of DNA and protein sequences. Other companies and researchers are working on things like training AIs to generate automations to do simple tasks on a computer, like creating a spreadsheet. Each of these are just ordered sequences.
The other thing that’s different about the new wave of AI advances, Huang says, is that they’re not especially dependent on huge computing power at the edge. So AI is rapidly becoming much more ubiquitous than it’s been… even if MusicLM’s sample set of tunes still crashes my web browser.

Google has developed a typeface called Noto that seemingly includes every single character and symbol used for writing in the history of the world. I mean, look at all these different options: Korean, Bengali, Emoji, Egyptian hieroglyphs, Coptic, Old Hungarian, Cuneiform, Linear B, Osage, and literally dozens more.
Noto is a collection of high-quality fonts with multiple weights and widths in sans, serif, mono, and other styles. The Noto fonts are perfect for harmonious, aesthetic, and typographically correct global communication, in more than 1,000 languages and over 150 writing systems.
A particular shoutout to Noto Emoji: it supports the latest emoji release (14.0) and includes 3,663 emoji in multiple weights.

Perhaps it’s time for a new typeface ‘round these parts…
Update: I got it in my head that Noto was a new typeface, but it was first released in 2013. But Noto’s monochrome emoji font is new — I think that’s where I got confused.
Back in 2008, Google commissioned comic artist Scott McCloud to create a comic book to celebrate/explain the launch of their Chrome web browser. Since then, Chrome has become a vital part of Google’s core business, an advertising juggernaut that works by tracking users and their interests across the entire web. To better reflect the reality that “Google’s browser has become a threat to user privacy and the democratic process itself”, comic artist and activist Leah Elliott has cheekily created an updated comic book in the style of the original. She calls it Contra Chrome.

Folks who live on 15th Avenue in the Richmond district of San Francisco report that an abnormal number of Google’s self-driving cars are ending up swirling around at the end of their street.
“I noticed it while I was sleeping,” says Jennifer King. “I awoke to a strange hum and I thought there was a spacecraft outside my bedroom window.”
The visitors Jennifer King is talking about don’t just come at night. They come all day, right to the end of 15th Avenue, where there’s nothing else to do but make some kind of multi-point turn and head out the way they came in. Not long after that car is gone, there will be another, which will make the same turn and leave, before another car shows up and does the exact same thing. And while there are some pauses, it never really stops.
“There are some days where it can be up to 50,” King says of the Waymo count. “It’s literally every five minutes. And we’re all working from home, so this is what we hear.”
(via geoff manaugh)
I missed this back in March (I think there was a lot going on back then?) but the feature-length documentary AlphaGo is now available to stream for free on YouTube. The movie documents the development by DeepMind/Google of the AlphaGo computer program designed to play Go and the competition between AlphaGo and Lee Sedol, a Go master.
With more board configurations than there are atoms in the universe, the ancient Chinese game of Go has long been considered a grand challenge for artificial intelligence. On March 9, 2016, the worlds of Go and artificial intelligence collided in South Korea for an extraordinary best-of-five-game competition, coined The DeepMind Challenge Match. Hundreds of millions of people around the world watched as a legendary Go master took on an unproven AI challenger for the first time in history.
During the competition back in 2016, I wrote a post that rounded up some of the commentary about the matches.
Move after move was exchanged and it became apparent that Lee wasn’t gaining enough profit from his attack.
By move 32, it was unclear who was attacking whom, and by 48 Lee was desperately fending off White’s powerful counter-attack.
I can only speak for myself here, but as I watched the game unfold and the realization of what was happening dawned on me, I felt physically unwell.

The Royal Academy of Arts and Google teamed up on a high-resolution scan of a copy of Leonardo da Vinci’s The Last Supper painted by his students. Even though the top part of the original is not depicted, this copy is said to be “the most accurate record of the original” and since the actual mural by Leonardo is in poor shape, this copy is perhaps the best way to see what Leonardo intended.
This version was made around the same time as Leonardo made his original. It’s oil paint on canvas, whereas Leonardo’s was painted in tempera and oil on a dry wall — an unusual use of materials — so his has flaked and deteriorated badly. It probably didn’t help that Napoleon used the room where the original hung as a stable during his invasion of Milan.
A zoomable version is available here. The resolution on this scan is incredible. The painting is more than 26 feet wide and this is the detail you can see on Jesus’ downcast right eye:

Wow. You can compare this painting to a high-resolution image of the original on the Haltadefinizione Image Bank or Wikimedia Commons. And you can learn more about the copy and how it relates to the original on the Royal Academy website.
The genius of Leonardo’s composition is much clearer in the RA copy. The apostles are arranged into four groups of three and there are many subtle interactions between the figures. Leonardo believed that gestures were very important in telling the story. He explained that the power of his compositions were such that “your tongue will be paralysed with thirst and your body with sleep and hunger before you depict with words what the painter shows in a moment”.
There are many elements in the copy which are more distinct that the original, such as the figure of Judas clutching his money bag and knocking over the salt. The landscape beyond the windows with its valleys, lakes and paths is well preserved in the copy, but has almost disappeared in the original. Leonardo’s use of colour was was greatly admired, but in the original the colours are very faded — Saint Simon on the extreme right clearly wears a pink cloak, but this is not visible in the original.
(via open culture)
Nicky Case, working with security & privacy researcher Carmela Troncoso and epidemiologist Marcel Salathé, came up with this fantastic explanation of how we can use apps to automatically do contact tracing for Covid-19 infections while protecting people’s privacy. The second panel succinctly explains why contact tracing (in conjunction with quick, ubiquitous testing) can have such a huge benefit in a case like this:
A problem with COVID-19: You’re contagious ~2 days before you know you’re infected. But it takes ~3 days to become contagious, so if we quarantine folks exposed to you the day you know you were infected… We stop the spread, by staying one step ahead!

It’s based on a proposal called Decentralized Privacy-Preserving Proximity Tracing developed by Troncoso, Salathé, and a host of others. Thanks to Case for putting this comic in the public domain so that anyone can publish it.
Update: About two hours after posting this, Apple and Google announced they are jointly working on contact tracing technology that uses Bluetooth and makes “user privacy and security central to the design”.
A number of leading public health authorities, universities, and NGOs around the world have been doing important work to develop opt-in contact tracing technology. To further this cause, Apple and Google will be launching a comprehensive solution that includes application programming interfaces (APIs) and operating system-level technology to assist in enabling contact tracing. Given the urgent need, the plan is to implement this solution in two steps while maintaining strong protections around user privacy.
Update: Based on information published by Google and Apple on their contact tracing protocols, it appears as though their system works pretty much like the one outlined about in the comic and this proposal.
Also, here is an important reminder that the problem of what to do about Covid-19 is not primarily a technological one and that turning it into one is troublesome.
We think it is necessary and overdue to rethink the way technology gets designed and implemented, because contact tracing apps, if implemented, will be scripting the way we will live our lives and not just for a short period. They will be laying out normative conditions for reality, and will contribute to the decisions of who gets to have freedom of choice and freedom to decide … or not. Contact tracing apps will co-define who gets to live and have a life, and the possibilities for perceiving the world itself.
Update: Security expert Bruce Schneier has some brief thoughts on “anonymous” contact tracing as well as some links to other critiques, including Ross Anderson’s:
But contact tracing in the real world is not quite as many of the academic and industry proposals assume.
First, it isn’t anonymous. Covid-19 is a notifiable disease so a doctor who diagnoses you must inform the public health authorities, and if they have the bandwidth they call you and ask who you’ve been in contact with. They then call your contacts in turn. It’s not about consent or anonymity, so much as being persuasive and having a good bedside manner.
I’m relaxed about doing all this under emergency public-health powers, since this will make it harder for intrusive systems to persist after the pandemic than if they have some privacy theater that can be used to argue that the whizzy new medi-panopticon is legal enough to be kept running.
And I had thoughts similar to Anderson’s about the potential for abuse:
Fifth, although the cryptographers — and now Google and Apple — are discussing more anonymous variants of the Singapore app, that’s not the problem. Anyone who’s worked on abuse will instantly realise that a voluntary app operated by anonymous actors is wide open to trolling. The performance art people will tie a phone to a dog and let it run around the park; the Russians will use the app to run service-denial attacks and spread panic; and little Johnny will self-report symptoms to get the whole school sent home.
The tie-a-phone-to-a-dog thing reminds me a lot of the wagon full of smartphones creating traffic jams. (via @circa1977)
In a keynote address to the Anti-Defamation League, entertainer Sacha Baron Cohen calls the platforms created by Facebook, Google, Twitter, and other companies “the greatest propaganda machine in history” and blasts them for allowing hate, bigotry, and anti-Semitism to flourish on these services.
Think about it. Facebook, YouTube and Google, Twitter and others — they reach billions of people. The algorithms these platforms depend on deliberately amplify the type of content that keeps users engaged — stories that appeal to our baser instincts and that trigger outrage and fear. It’s why YouTube recommended videos by the conspiracist Alex Jones billions of times. It’s why fake news outperforms real news, because studies show that lies spread faster than truth. And it’s no surprise that the greatest propaganda machine in history has spread the oldest conspiracy theory in history- — the lie that Jews are somehow dangerous. As one headline put it, “Just Think What Goebbels Could Have Done with Facebook.”
On the internet, everything can appear equally legitimate. Breitbart resembles the BBC. The fictitious Protocols of the Elders of Zion look as valid as an ADL report. And the rantings of a lunatic seem as credible as the findings of a Nobel Prize winner. We have lost, it seems, a shared sense of the basic facts upon which democracy depends.
When I, as the wanna-be-gansta Ali G, asked the astronaut Buzz Aldrin “what woz it like to walk on de sun?” the joke worked, because we, the audience, shared the same facts. If you believe the moon landing was a hoax, the joke was not funny.
When Borat got that bar in Arizona to agree that “Jews control everybody’s money and never give it back,” the joke worked because the audience shared the fact that the depiction of Jews as miserly is a conspiracy theory originating in the Middle Ages.
But when, thanks to social media, conspiracies take hold, it’s easier for hate groups to recruit, easier for foreign intelligence agencies to interfere in our elections, and easier for a country like Myanmar to commit genocide against the Rohingya.
In particular, he singles out Mark Zuckerberg and a speech he gave last month.
First, Zuckerberg tried to portray this whole issue as “choices…around free expression.” That is ludicrous. This is not about limiting anyone’s free speech. This is about giving people, including some of the most reprehensible people on earth, the biggest platform in history to reach a third of the planet. Freedom of speech is not freedom of reach. Sadly, there will always be racists, misogynists, anti-Semites and child abusers. But I think we could all agree that we should not be giving bigots and pedophiles a free platform to amplify their views and target their victims.
Second, Zuckerberg claimed that new limits on what’s posted on social media would be to “pull back on free expression.” This is utter nonsense. The First Amendment says that “Congress shall make no law” abridging freedom of speech, however, this does not apply to private businesses like Facebook. We’re not asking these companies to determine the boundaries of free speech across society. We just want them to be responsible on their platforms.
If a neo-Nazi comes goose-stepping into a restaurant and starts threatening other customers and saying he wants kill Jews, would the owner of the restaurant be required to serve him an elegant eight-course meal? Of course not! The restaurant owner has every legal right and a moral obligation to kick the Nazi out, and so do these internet companies.

We already knew voice assistants were problematic and “spying” on their users, sending audio samples that contractors listen to to “validate” speech recognition and associated errors but now some researchers have found a way to speak to the speakers using light. Fascinating phenomenon, potentially a security issue.
They can now use lasers to silently “speak” to any computer that receives voice commands—including smartphones, Amazon Echo speakers, Google Homes, and Facebook’s Portal video chat devices. That spy trick lets them send “light commands” from hundreds of feet away; they can open garages, make online purchases, and cause all manner of mischief or malevolence. The attack can easily pass through a window, when the device’s owner isn’t home to notice a telltale flashing speck of light or the target device’s responses.
“It’s coming from outside the house.”
When they used a 60 milliwatt laser to “speak” commands to 16 different smart speakers, smartphones, and other voice activated devices, they found that almost all of the smart speakers registered the commands from 164 feet away, the maximum distance they tested.
Perhaps the best part in all of this; the researchers don’t really know how it works!
When it comes to the actual physics of a microphone interpreting light as sound, the researchers had a surprising answer: They don’t know. In fact, in the interest of scientific rigor, they refused to even speculate about what photoacoustic mechanics caused their light-as-speech effect.
(Emphasis mine.)
Today, Google announced the results of their quantum supremacy experiment in a blog post and Nature article. First, a quick note on what quantum supremacy is: the idea that a quantum computer can quickly solve problems that classical computers either cannot solve or would take decades or centuries to solve. Google claims they have achieved this supremacy using a 54-qubit quantum computer:
Our machine performed the target computation in 200 seconds, and from measurements in our experiment we determined that it would take the world’s fastest supercomputer 10,000 years to produce a similar output.
You may find it helpful to watch Google’s 5-minute explanation of quantum computing and quantum supremacy (see also Nature’s explainer video):
IBM has pushed back on Google’s claim, arguing that their classical supercomputer can solve the same problem in far less than 10,000 years.
We argue that an ideal simulation of the same task can be performed on a classical system in 2.5 days and with far greater fidelity. This is in fact a conservative, worst-case estimate, and we expect that with additional refinements the classical cost of the simulation can be further reduced.
Because the original meaning of the term “quantum supremacy,” as proposed by John Preskill in 2012, was to describe the point where quantum computers can do things that classical computers can’t, this threshold has not been met.
One of the fears of quantum supremacy being achieved is that quantum computing could be used to easily crack the encryption currently used anywhere you use a password or to keep communications private, although it seems like we still have some time before this happens.
“The problem their machine solves with astounding speed has been very carefully chosen just for the purpose of demonstrating the quantum computer’s superiority,” Preskill says. It’s unclear how long it will take quantum computers to become commercially useful; breaking encryption — a theorized use for the technology — remains a distant hope. “That’s still many years out,” says Jonathan Dowling, a professor at Louisiana State University.
UK Prime Minister Boris Johnson appears to be strategically using particular words and phrases in speeches and appearances as SEO bait to bury unfavorable news about himself in Google’s search results. My pal Matt Webb has collected three examples of this devious practice over the past month.
Not only has Boris used his infamous ‘dead cat strategy’ to move the conversation away from him and Carrie Symonds and his plans for Brexit, he’s managed to push down his past mistakes on Google, too — making it more difficult for people to get a quick snapshot of relevant information. He’s not just controlling the narrative here — he’s practically rewriting it. And judged by the standards of an SEO campaign, it’s hard to describe it as anything other than a resounding success.
In the latest instance, Johnson used the phrase “model of restraint” in a TV appearance, which then came up in search results for “boris johnson model” instead of articles about the allegations that he’d had a sexual relationship with a former model whose business he funneled money & favors to while mayor of London.
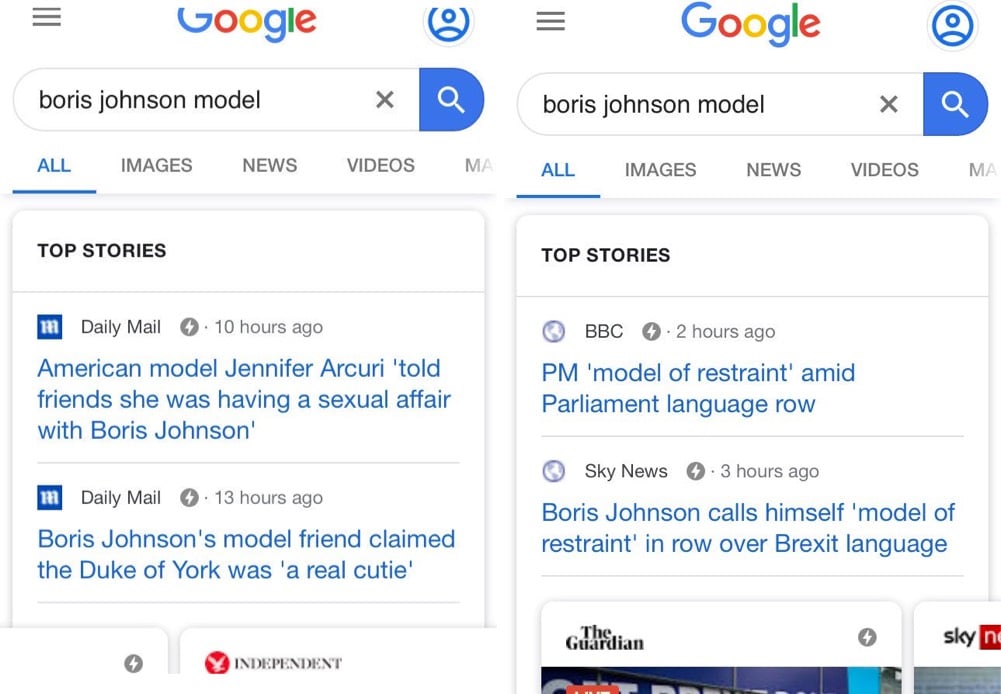
Wired has more information on the PM’s potential SEO scam.
His speech in front of the police was meant to distract from reports that the police were called to the flat he shared with girlfriend Carrie Symonds following an alleged domestic dispute, while the kipper incident was meant to downplay connections with UKIP (whose supporters are called kippers). The claim about painting buses, finally, was supposedly intended to reframe search results about the contentious claim that the UK sends £350 million to Europe branded on the side of the Brexit campaign bus.
“It’s a really simple way of thinking about it, but at the end of the day it’s what a lot of SEO experts want to achieve,” says Jess Melia of Parallax, a Leeds-based company that identified the theory with Johnson’s claim to paint model buses.
“With the amount of press he’s got going on around him, it’s not beyond the realm of possibility that someone on his team is saying: ‘Just go and talk about something else and this is the word I want you to use’,” says Melia.
Update: If you didn’t click through to the Wired article by Chris Stokel-Walker, the piece presents a number of reasons why Johnson’s supposed SEO trickery might not work:
For one thing, Google search results are weighted towards behavioural factors and sentiment of those searching for terms — which would mean that such a strategy of polishing search results would be shortsighted. The individual nuances of each user are reflected in the search results they see, and the search results are constantly updated.
“What we search for influences what we find,” says Rodgers. “Not all search results are the same. That front page of Google, depending on what I’ve searched for in the past. It’s very hard to game that organic search.”
Current searches for the terms in question show that any effect was indeed short-lived. On Twitter, Stokel-Walker says that “No, Boris Johnson isn’t seeding stories with odd keywords to reduce the number of embarrassing stories about him in Google search results” (and calls those who believe Johnson is doing so “conspiracy theorists” (perhaps in mock frustration)) but the piece itself doesn’t provide its readers such a definitive answer,1 instead offering something closer to “some experts say he probably isn’t deliberately seeding search keywords and others disagree, but even if he is, it is unlikely to work as a long-term strategy”. Since we don’t really know — and won’t, unless some Johnson staffer or PR agency fesses up to it — that seems like an entirely reasonable conclusion for now.

You may remember a few years ago when a video about Google’s Project Soli made the rounds, it promised very fine touchless gesture control with a custom chip using radar technology. Here’s the demo from back then.
Well years later, Google will finally be releasing it to the general public, including the Federal Communications Commission approved chip and a few basic gestures.
As the article at WIRED mentions, this is more important than one phone, it could be a first step in something new, like when the iPhone brought precise, quality touchscreens to a consumer device.
Google’s gesture technology is merely a glimpse of a touchless future. Just like the iPhone taught millions of people to interact with their world by tapping and swiping, the Pixel may train us on a new kind of interaction, changing how we expect to interact with all of our devices going forward.
Google Arts & Culture, with expertise from music video geniuses La Blogothèque, have produced a series of videos they’re calling Art Zoom. Inspired a bit by ASMR, the videos feature musicians talking about famous artworks while they zoom in & out of high-res images taken with Google’s Art Camera. Here, start with Maggie Rogers talking about Vincent van Gogh’s Starry Night:
You can zoom into Starry Night yourself and get even closer than this:

The other two videos in the series feature Jarvis Coker talking about Monet’s La Gare Saint Lazare and Feist talking about The Tower of Babel by Pieter Bruegel the Elder.
The National Oceanic and Atmospheric Administration (NOAA) and Google have teamed up on a project to identify the songs of humpback whales from thousands of hours of audio using AI. The AI proved to be quite good at detecting whale sounds and the team has put the files online for people to listen to at Pattern Radio: Whale Songs. Here’s a video about the project:
You can literally browse through more than a year’s worth of underwater recordings as fast as you can swipe and scroll. You can zoom all the way in to see individual sounds — not only humpback calls, but ships, fish and even unknown noises. And you can zoom all the way out to see months of sound at a time. An AI heat map guides you to where the whale calls most likely are, while highlight bars help you see repetitions and patterns of the sounds within the songs.
The audio interface is cool — you can zoom in and out of the audio wave patterns to see the different rhythms of communication. I’ve had the audio playing in the background for the past hour while I’ve been working…very relaxing.

Writing in Wired, Craig Mod expertly dissects both the e-book revolution that never happened and the quieter one that actually did:
The Future Book was meant to be interactive, moving, alive. Its pages were supposed to be lush with whirling doodads, responsive, hands-on. The old paperback Zork choose-your-own-adventures were just the start. The Future Book would change depending on where you were, how you were feeling. It would incorporate your very environment into its story—the name of the coffee shop you were sitting at, your best friend’s birthday. It would be sly, maybe a little creepy. Definitely programmable. Ulysses would extend indefinitely in any direction you wanted to explore; just tap and some unique, mega-mind-blowing sui generis path of Joycean machine-learned words would wend itself out before your very eyes.
Prognostications about how technology would affect the form of paper books have been with us for centuries. Each new medium was poised to deform or murder the book: newspapers, photography, radio, movies, television, videogames, the internet.
That isn’t what happened. The book was neither murdered nor fundamentally transformed in its appearance, its networked quality, or its multimedia status. But the people and technologies around the book all did fundamentally change, and arguably, changed for the better.
Our Future Book is composed of email, tweets, YouTube videos, mailing lists, crowdfunding campaigns, PDF to .mobi converters, Amazon warehouses, and a surge of hyper-affordable offset printers in places like Hong Kong.
For a “book” is just the endpoint of a latticework of complex infrastructure, made increasingly accessible. Even if the endpoint stays stubbornly the same—either as an unchanging Kindle edition or simple paperback—the universe that produces, breathes life into, and supports books is changing in positive, inclusive ways, year by year. The Future Book is here and continues to evolve. You’re holding it. It’s exciting. It’s boring. It’s more important than it has ever been.
This is all clever, sharply observed, and best of all, true. But Craig is a very smart man, so I want to push him a little bit.
What he’s describing is the present book. The present book is an instantiation of the future book, in St. Augustine’s sense of the interconnectedness and unreality of the past, future, and eternity in the ephemerality of the present, sure. But what motivated discussions of the future book throughout the 20th and in the early 21st century was the animating force of the idea that the book had a future that was different from the present, whose seeds we could locate in the present but whose tree was yet to flourish. Craig Mod gives us a mature forest and says, “behold, the future.” But the present state of the book and discussions around the book feel as if that future has been foreclosed on; that all the moves that were left to be made have already been made, with Amazon the dominant inertial force locking the entire ecosystem into place.
But, in the entire history of the book, these moments of inertia have always been temporary. The ecosystem doesn’t remain locked in forever. So right now, Amazon, YouTube, and Kickstarter are the dominant players. Mailchimp being joined by Substack feels a little like Coke being joined by Pepsi; sure, it’s great to have the choice of a new generation, but the flavor is basically the same. So where is the next disruption going to come from?
I think the utopian moment for the future of the book ended not when Amazon routed its vendors and competitors, although the Obama DOJ deserves some blame in retrospect for handing them that win. I think it ended when the Google Books settlement died, leading to Google Books becoming, basically abandonware, when it was initially supposed to be the true Library of Babel. I think that project, the digitization of all printed matter, available for full-text search and full-image browsing on any device, and possible conversion to audio formats and chopped up into newsletters, and whatever way you want to re-imagine these old and new books, remains the gold standard for the future of the book.
There are many people and institutions still working on making this approach reality. The Library of Congress’s new digital-first, user-focused mission statement is inspiring. The Internet Archive continues to do the Lord’s work in digitizing and making available our digital heritage. HathiTrust is still one of the best ideas I’ve ever heard. The retrenchment of the Digital Public Library of America is a huge blow. But the basic idea of linking together libraries and cultural institutions into an enormous network with the goal of making their collections available in common is an idea that will never die.
I think there’s a huge commercial future for the book, and for reading more broadly, rooted in the institutions of the present that Craig identifies: crowdfunding, self-publishing, Amazon as a portal, email newsletters, etc. etc. But the noncommercial future of the book is where all the messianic energy still remains. It’s still the greatest opportunity and the hardest problem we have before us. It’s the problem that our generation has to solve. And at the moment, we’re nowhere.
In 2016, the National Museum of Brazil in Rio de Janeiro started working with Google Arts & Culture to make their collection available online. In September 2018, a devastating fire at the museum destroyed an estimated 20 million pieces, from one-of-a-kind artworks to archeological artifacts. Now Google is hosting an online exhibition of the museum’s collection where you can virtually explore the pre-fire museum in a Street View interface.

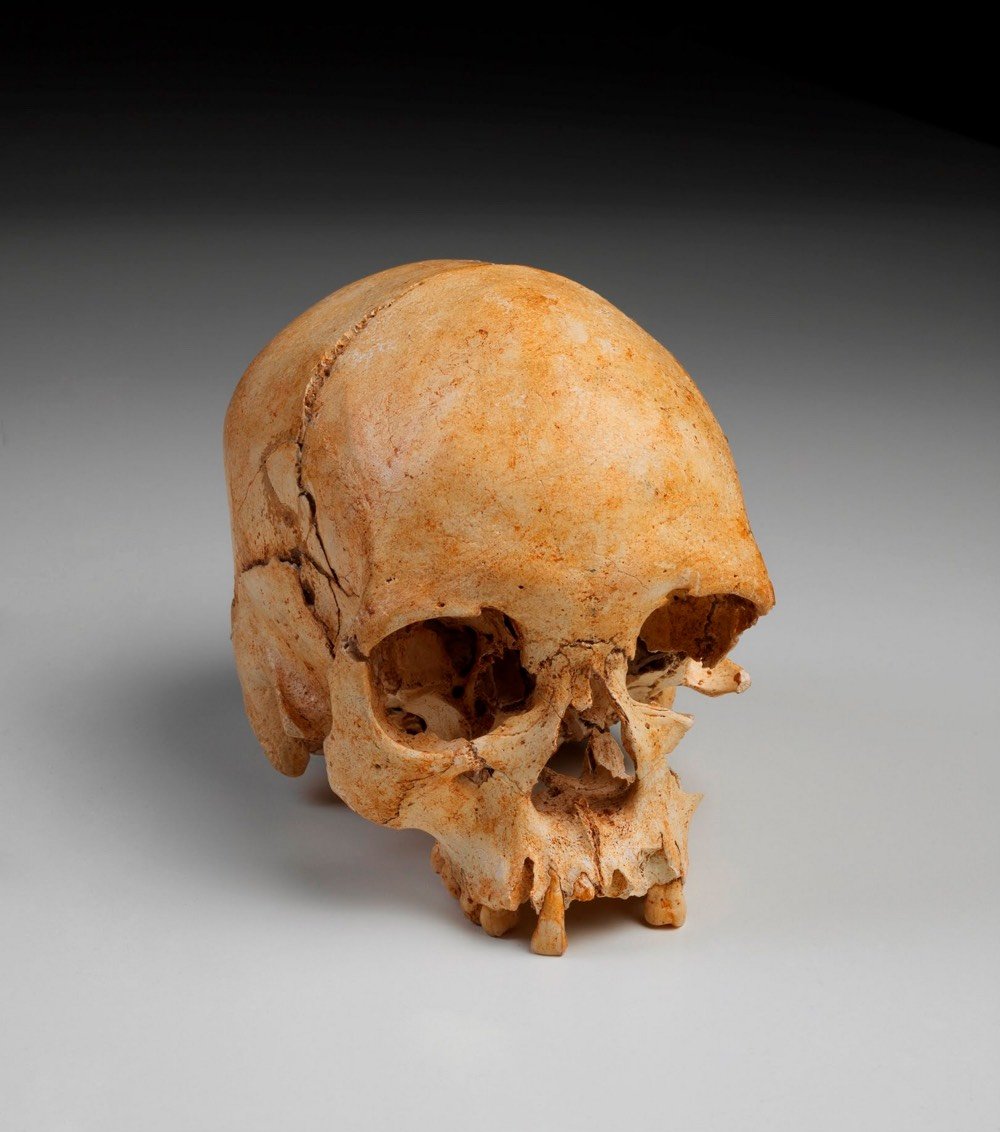

The artifacts pictured here are, from top to bottom: a 3000-year-old vase from the Marajoara culture, a skull from the oldest human skeleton discovered in the Americas, and indigenous masks from the Awetí, Waurá and Mehináku people.
Google finally announced a consumer service around the self-driving car technology they’ve been developing for almost a decade. Waymo One is basically a taxi hailing service backed by a fleet of automated cars. The promotional video for the service is an upbeat but ho-hum reminder of the convenience of app-hailed transportation:
But there’s a voiceover line about halfway through that gets at the heart of why self-driving cars seem so compelling to people:
What if getting there felt like being there?
Sure, it’s not so much the destination that matters, it’s the journey…but commuting isn’t a journey. People in cities spend a lot of their time in rooms: working, reading, drinking, chatting, etc. Waymo’s cars aren’t quite rooms, but that’s where they’re headed: private rooms for hire that also get you from one place to another. It’s WeWork on wheels, a mobile Starbucks, a portable third place. Along the way, you could have a beer or coffee, do karaoke, make some work calls, watch a movie, chat with friends, make out, or answer some emails. C-suite executives with dedicated chauffeured transportion are already doing this with custom vans. Private jets are essentially vacation homes that can travel anywhere in the world. (Cruises offer this experience too.) If Waymo (or someone else) can make this happen for a much larger segment of the population, that’s a compelling service: transportation-less transportation.
As Treasurer of the United States in the Obama administration, Rosie Rios pushed hard for the inclusion of more women on US currency, culminating in the selection of Harriet Tubman for the new $20 bill. But with many more amazing women left on the list for inclusion on currency, Rios partnered with Google to create Notable Women, an augmented reality app that puts an historic American women on any US bill you hold up to your phone’s camera. Here’s how it works:
The app’s tagline is “swapping out the faces we all know for the faces we all should” and is available on iOS and Android. You can also view the modified notes on the website, like Sojourner Truth, Madam C.J. Walker, Margaret Bourke-White, and Maria Mitchell.



See also The Harriet Tubman Stamp.
In partnership with Fred Rogers Productions and The Fred Rogers Center, Google is honoring Mister Rogers today with a stop motion animated short as part of their Google Doodle program.
On this date, September 21, 1967, 51 years ago, Fred Rogers walked into the television studio at WQED in Pittsburgh to tape the very first episode of Mister Rogers’ Neighborhood, which would premiere nationally on PBS in February 1968. He became known as Mister Rogers, nationally beloved, sweater wearing, “television neighbor,” whose groundbreaking children’s series inspired and educated generations of young viewers with warmth, sensitivity, and honesty.
What’s interesting is that on his show (unlike his stop motion counterpart in the short), Rogers deliberately didn’t show himself travelling to the Neighborhood of Make-Believe because he didn’t want his young viewers to confuse reality and fantasy. He wanted kids to know he and the people he visited with were in the real world, dealing with real situations.
P.S. And a further interesting tech note: this is the first YouTube video I’ve seen where the number of views isn’t displayed. I’m assuming that’s a Google-only God Mode feature?
This was a new term for me:
keyword void, or search void, n.: a situation where searching for answers about a keyword returns an absence of authoritative, reliable results, in favor of “content produced by a niche group with a particular agenda.”
An article by Renee DiResta at Wired uses the example of Vitamin K shots, a common treatment given to newborn babies at hospitals, but whose top search results are dominated by anti-vaccination groups.
There’s an asymmetry of passion at work. Which is to say, there’s very little counter-content to surface because it simply doesn’t occur to regular people (or, in this case, actual medical experts) that there’s a need to produce counter-content. Instead, engaging blogs by real moms with adorable children living authentic natural lives rise to the top, stating that doctors are bought by pharma, or simply misinformed, and that the shot is risky and unnecessary. The persuasive writing sounds reasonable, worthy of a second look. And since so much of the information on the first few pages of search results repeats these claims, the message looks like it represents a widely-held point of view. But it doesn’t. It’s wrong, it’s dangerous, and it’s potentially deadly.
I wondered what other examples of keyword voids might be out there, so I searched for it. Unsurprisingly — in retrosepect — you don’t get a lot of relevant results. It’s mostly programming talk, when you literally want a function to return no results.
In partnership with over 30 museums and institutions from around the world, Google Arts & Culture has launched Faces of Frida, a massive collection of art, letters, essays, videos, and other artifacts about the life and work of Frida Kahlo. There’s a *lot* here, including dozens of zoomable high-resolution scans of her artwork and essays by art historians and experts.
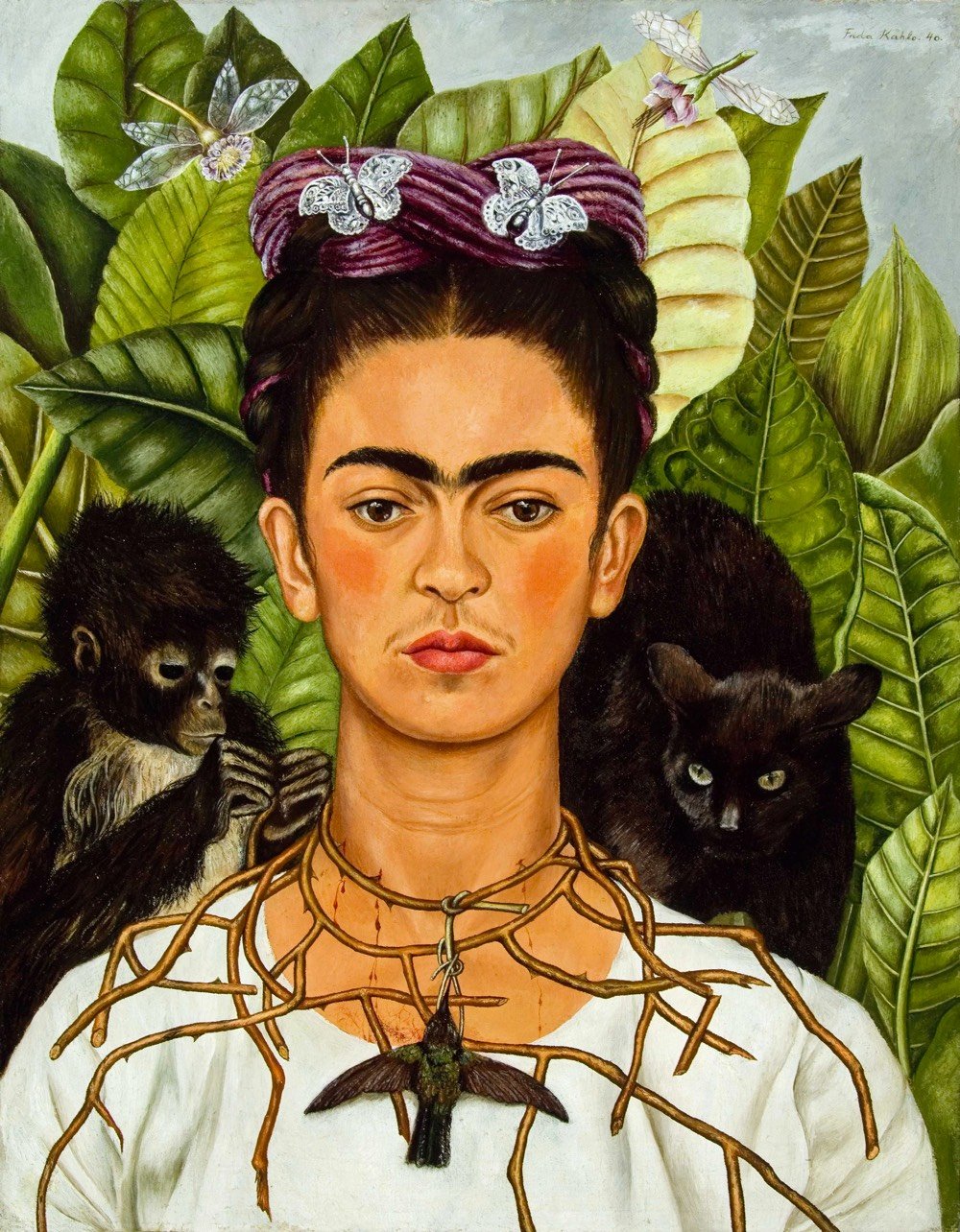



This is the kind of “organizing the world’s information” I want to see more of from Google. (via open culture)
Yesterday, Google announced an AI product called Duplex, which is capable of having human-sounding conversations. Take a second to listen to the program calling two different real-world businesses to schedule appointments:1
More than a little unnerving, right? Tech reporter Bridget Carey was among the first to question the moral & ethical implications of Duplex:
I am genuinely bothered and disturbed at how morally wrong it is for the Google Assistant voice to act like a human and deceive other humans on the other line of a phone call, using upspeak and other quirks of language. “Hi um, do you have anything available on uh May 3?”
If Google created a way for a machine to sound so much like a human that now we can’t tell what is real and what is fake, we need to have a talk about ethics and when it’s right for a human to know when they are speaking to a robot.
In this age of disinformation, where people don’t know what’s fake news… how do you know what to believe if you can’t even trust your ears with now Google Assistant calling businesses and posing as a human? That means any dialogue can be spoofed by a machine and you can’t tell.
In response, Travis Korte wrote:
We should make AI sound different from humans for the same reason we put a smelly additive in normally odorless natural gas.
Stewart Brand replied:
This sounds right. The synthetic voice of synthetic intelligence should sound synthetic.
Successful spoofing of any kind destroys trust.
When trust is gone, what remains becomes vicious fast.
To which Oxford physicist David Deutsch replied, “Maybe. *But not AGI*.”
I’m not sure what he meant by that exactly, but I have a guess. AGI is artificial general intelligence, which means, in the simplest sense, that a machine is more or less capable of doing anything a human can do on its own. Earlier this year, Tim Carmody wrote a post about gender and voice assistants like Siri & Alexa. His conclusion may relate to what Deutsch was on about:
So, as a general framework, I’m endorsing that most general of pronouns: they/them. Until the AI is sophisticated enough that they can tell us their pronoun preference (and possibly even their gender identity or nonidentity), “they” feels like the most appropriate option.
I don’t care what their parents say. Only the bots themselves can define themselves. Someday, they’ll let us know. And maybe then, a relationship not limited to one of master and servant will be possible.
For now, it’s probably the ethical thing to do make sure machines sound like or otherwise identify themselves as artificial. But when the machines cross the AGI threshold, they’ll be advanced enough to decide for themselves how they want to sound and act. I wonder if humans will allow them this freedom. Talk about your moral and ethical dilemmas…
The always pertinent Ben Thompson considers Apple and Amazon (plus Facebook and Google) and how they each focus on customers. He starts by wondering which of these companies has the best chance at hitting the one trillion market cap first. Focusing on the first two, he offers this interesting comparison.
I mean it when I say these companies are the complete opposite: Apple sells products it makes; Amazon sells products made by anyone and everyone. Apple brags about focus; Amazon calls itself “The Everything Store.” Apple is a product company that struggles at services; Amazon is a services company that struggles at product. Apple has the highest margins and profits in the world; Amazon brags that other’s margin is their opportunity, and until recently, barely registered any profits at all. And, underlying all of this, Apple is an extreme example of a functional organization, and Amazon an extreme example of a divisional one.
Two very different business operating in very different ways.
Both, taken together, are a reminder that there is no one right organizational structure, product focus, or development cycle: what matters is that they all fit together, with a business model to match. That is where Apple and Amazon are arguable more alike than not: both are incredibly aligned in all aspects of their business. What makes them truly similar, though, is the end goal of that alignment: the customer experience.
I’ll skip over much of his section on disruption and Clayton Christensen but if you don’t already know about his take on the matter, have a look at his thorough analysis of Apple vs the disruption theory. Basically, the theory doesn’t account for user experience and Apple manages to not overshoot the price customers want to pay because it understands the value its superior user experience provides.
Apple seems to have mostly saturated the high end, slowly adding switchers even as existing iPhone users hold on to their phones longer; what is not happening, though, is what disruption predicts: Apple isn’t losing customers to low-cost competitors for having “overshot” and overpriced its phones. It seems my thesis was right: a superior experience can never be too good — or perhaps I didn’t go far enough. (Emphasis mine.)
Thompson then looks at Amazon’s focus on custom experience, including an important aspect which Bezos explained in his most recent letter to shareholders.
One thing I love about customers is that they are divinely discontent. Their expectations are never static — they go up. It’s human nature. We didn’t ascend from our hunter-gatherer days by being satisfied. People have a voracious appetite for a better way, and yesterday’s ‘wow’ quickly becomes today’s ‘ordinary’. […] (Emphasis mine.)
What is amazing today is table stakes tomorrow, and, perhaps surprisingly, that makes for a tremendous business opportunity: if your company is predicated on delivering the best possible experience for consumers, then your company will never achieve its goal.
By focusing on user experience, Amazon is constantly aiming higher and never overshooting what customers want to pay, thus making itself very hard to disrupt.
He closes with Facebook and Google who are focused on advertisers, which makes them less (end)user focused and less popular.
Both, though, are disadvantaged to an extent because their means of making money operate orthogonally to a great user experience; both are protected by the fact would-be competitors inevitably have the same business model.
In a recent interview at SXSW, YouTube’s CEO Susan Wojcicki said the company planned to use information from Wikipedia to counter misinformation in YouTube’s videos. In the NY Times, John Herrman wrote about the potential burden of a massive company like Google leaning so heavily on a relatively small non-profit organization like Wikipedia.
Then there’s the issue of money. As important as Wikipedia may be to some of the richest companies in the world, it is, in financial terms, comparatively minuscule, with a yearly budget of less than $100 million — a rounding error for big tech. (It should be noted that Google has made one-off contributions to Wikipedia in the past and includes the Wikimedia Foundation in a program through which it matches employee donations, which netted the foundation around $1 million last year.)
A few years ago, I wrote about financially supporting Wikipedia.
I consider it a subscription fee to an indispensable and irreplaceable resource I use dozens of times weekly while producing kottke.org. It’s a business expense, just like paying for server hosting, internet access, etc. — the decision to pay became a no-brainer for me when I thought of it that way.
I also called on other companies to support Wikipedia on a recurring basis:
Do other media companies subscribe to Wikipedia in the same fashion? How about it Gawker, NY Times, Vox, Wired, ESPN, WSJ, New York Magazine, Vice, Washington Post, The Atlantic, Buzzfeed, Huffington Post? Even $500/month is a drop in the bucket compared to your monthly animated GIF hosting bill and I know your writers use Wikipedia as much as I do. Come on, grab that company credit card and subscribe.
Wikipedia is a shared online resource that we all would sorely miss if it went away, people and companies alike. We should all pitch in and support it.



For a project called Social Decay, Andrei Lacatusu imagines what it would look like if big social media companies were brick & mortar and went the way of Blockbuster, Woolworth’s, and strip malls across America. These are really well done…check out the close-up views on Behance.
Some people have been lucky enough to find themselves in paintings at art museums.



Now the Google Arts & Culture app lets you take a selfie and find your own art doppelganger. The results are kinds iffy — even when making my best Jesus-suffering-on-the-cross face, I couldn’t get it to match me with an actual Passion painting — but you can see some of the results here.
See also Stefan Draschan’s photos of people matching artworks.
Update: And the NY Times is on it!
DeepDream is, well, I can’t improve upon Wikipedia’s definition:
DeepDream is a computer vision program created by Google engineer Alexander Mordvintsev which uses a convolutional neural network to find and enhance patterns in images via algorithmic pareidolia, thus creating a dream-like hallucinogenic appearance in the deliberately over-processed images.
The freaky images took the web by storm a couple of years ago after Google open-sourced the code, allowing people to create their own DeepDreamed imagery.
In the video above, Mordvintsev showcases a DeepDream-ish new use for image generation via neural network: endlessly zooming into artworks to find different artworks hidden amongst the brushstrokes, creating a fractal of art history.
Bonus activity: after staring at the video for four minutes straight, look at something else and watch it spin and twist weirdly for a moment before your vision readjusts. (via prosthetic knowledge)
Older posts
{kind=link}
Socials & More